






阿里雲通義千問發佈多款AI大模型 多模態、長文本能力全面升級
近日阿里雲旗下的通義千問發佈性能強大的旗艦版Qwen2.5-Max,並開源升級版視覺理解模型Qwen2.5-VL以及支持百萬token長文本處理的Qwen2.5-1M,不僅展現了通義千問在大模型前沿技術領域的探索成果,更為開發者和企業提供了有力的技術支持。
旗艦版Qwen2.5-Max:對MoE模型最新探索成果
通義千問旗升級版艦版模型Qwen2.5-Max,是對MoE模型的最新探索成果,預訓練數據超過20萬億tokens,綜合性能強勁,在多項主流模型評測基準上錄得高分。目前,開發者可在Qwen Chat平台體驗模型,企業和機構也可通過阿里雲百鍊平台直接調用新模型API服務。
Qwen2.5-Max在知識(測試大學水平知識的MMLU-Pro)、編程(LiveCodeBench)、全面評估綜合能力的(LiveBench)以及人類偏好對齊(Arena-Hard)等主流權威基準測試上,通義團隊分別對Qwen2.5-Max的指令(Instruct)模型版本和基座(base)模型版本性能進行了評估測試。
指令模型是所有人可直接對話體驗到的模型版本,在 Arena-Hard、LiveBench、LiveCodeBench 和 GPQA-Diamond 等基準測試中,Qwen2.5-Max 的表現超越了 DeepSeek V3。同時在 MMLU-Pro 等其他評估中也展現出了極具競爭力的成績。
Qwen2.5-Max更是在評估全球最佳大語言模型和AI聊天機器人的權威三方基準測試平台Chatbot Arena取得矚目成績。Qwen2.5-Max在Chatbot Arena最新公佈的大模型盲測榜單中,總分全球排名第七,與其他頂級大模型不相上下,它在數學和和編程等單項能力上排名第一,在硬提示(hard prompts),即解決挑戰性任務的複雜提示方面排名第二。
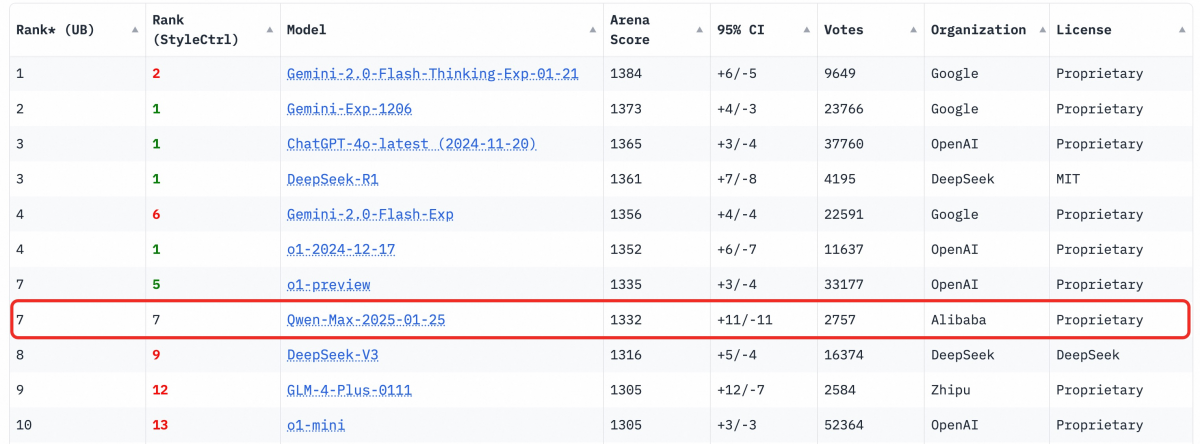
Qwen2.5-Max在Chatbot Arena最新公佈的大模型榜單中排名亮眼
視覺理解模型Qwen2.5-VL多模態處理能力顯著提升
通義千問還開源了全新的視覺理解模型Qwen2.5-VL,推出3B、7B和72B三個尺寸版本。其中,旗艦版Qwen2.5-VL-72B在13項權威評測中奪得視覺理解冠軍。目前,不同尺寸及量化版本的Qwen2.5-VL模型已在魔搭社區ModelScope、HuggingFace等平台開源,開發者也可以在Qwen Chat上直接體驗最新模型。
Qwen2.5-VL展現強大多模態能力,不僅能精準識別物體和解析複雜圖像內容,還可理解一小時以上的長視頻,精確回答問題。此外,該模型能將非結構化數據如發票、表單轉換為JSON等結構化格式,特別適合自動生成財報和法務文檔等場景。
Qwen2.5-VL甚至能夠直接作為視覺智能體進行操作,通過指導使用各種工具,在電腦和移動設備上輕鬆執行查詢天氣、訂機票等多步驟任務。
在模型技術方面,與上一代Qwen2-VL相比,Qwen2.5-VL增強了模型對時間和空間尺度的感知能力,並進一步簡化了網絡結構以提高模型效率。在重要的視覺編碼器設計中,通義團隊從頭開始訓練了原生動態分辨率的ViT,並採用創新結構,讓Qwen2.5-VL擁有更簡潔高效的視覺編解碼能力。
演示輸入簡單指令讓Qwen-VL 2.5在booking上預訂機票

Qwen2.5-VL評分圖
Qwen2.5-1M突破百萬Token
此外,阿里雲通義還開源了支持100萬Tokens上下文的Qwen2.5-1M模型,推出7B及14B兩個尺寸,同時開源推理框架,在處理百萬級別長文本輸入時可實現近7倍的提速。
Qwen2.5-1M已經在ModelScope和HuggingFace等平台開源,相關推理框架也已在GitHub上開源,開發者和企業也可通過阿里雲百鍊平台調用 Qwen2.5-Turbo模型API,或是通過Qwen Chat體驗模型性能及效果。
Qwen2.5-1M擁有優異的長文本處理能力。在上下文長度為100萬Tokens的大海撈針(Passkey Retrieval)任務中,Qwen2.5-1M 能夠準確地從 1M 長度的文檔中檢索出隱藏信息,僅有7B模型出現了少量錯誤。在RULER、LV-Eval等基準對複雜長上下文理解任務測試中,Qwen2.5-14B-Instruct-1M表現出色,為開發者提供了一個現有長上下文模型的優秀開源替代。
長文本訓練需大量計算資源,通義團隊將Qwen2.5-1M的上下文長度從4K逐步擴展到256K,再通過Dual Chunk Attention機制,無需額外訓練即可將上下文穩定擴展到1M。同時,團隊在vLLM引擎基礎上引入稀疏注意力機制,在多個環節進行創新優化,提高推理效率。
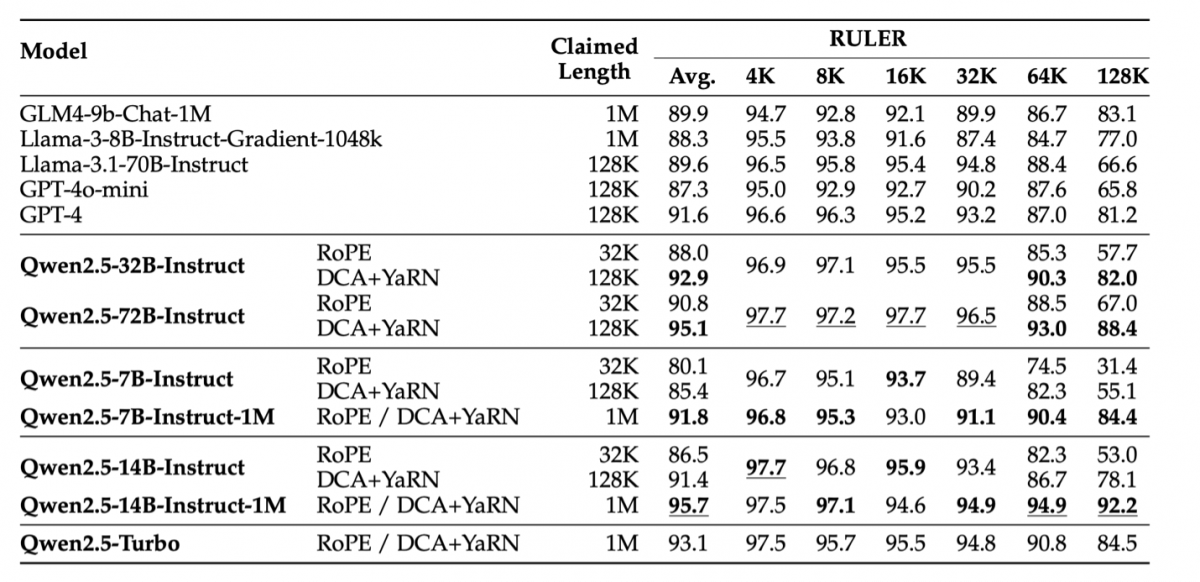
Qwen 2.5系列模型在RULER上的表現
立即訂閱阿里足跡,緊貼阿里巴巴集團最新發展動向,通過新聞故事及專題文章了解創新科技、電子商務及智能物流等新興議題的嶄新趨勢


分享